
MySQL NDB Cluster使用及性能测试
MySQL集群是一种在无共享架构(SNA,Share Nothing Architecture)系统里应用内存数据库集群的技术。这种无共享的架构可以使得系统使用低廉的硬件获取高的可扩展性。
MySQL集群是一种分布式设计,目标是要达到没有任何单点故障点。因此,任何组成部分都应该拥有自己的内存和磁盘。任何共享存储方案如网络共享,网络文件系统和SAN设备是不推荐或不支持的。通过这种冗余设计,MySQL声称数据的可用度可以达到99.999%。
实际上,MySQL集群是把一个叫做NDB的内存集群存储引擎集成与标准的MySQL服务器集成。它包含一组计算机,每个都跑一个或者多个进程,这可能包括一个MySQL服务器,一个数据节点,一个管理服务器和一个专有的一个数据访问程序。
概念介绍
成员角色
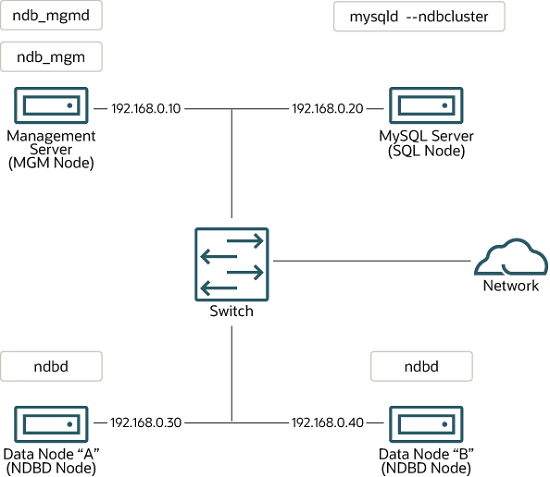
管理节点(MGM)
用来实现整个集群的管理,理论上一般只启动一个,而且宕机也不影响 cluster 的服务,这个进程只在cluster 启动以及节点加入集群时起作用, 所以这个节点不是很需要冗余,理论上通过一台服务器提供服务就可以了。通过 ndb_mgmd 命令启动,使用 config.ini 配置文件。数据节点(NDB)
用来存储数据,可以和管理节点(MGM)、 用户端节点(API)处在不同的机器上,也可以在同一个机器上面,集群中至少要有一个DB节点,2个以上 时就能实现集群的高可用保证,DB节点增加时,集群的处理速度会变慢。通过 ndbd 命令启动,第一次创建好cluster DB 节点时,需要使用 –init参数初始化。客户端节点(API)
通过他实现 Cluster DB 的访问,这个节点也可以是普通的 mysqld 进程,也可以是空节点,提供给外界连接,如JAVA程序。 需要在配置文件中配置ndbcluster 指令打开 NDB Cluster storage engine 存储引擎,增加 API 节点会提高整个集群的并发访问速度和整体的吞吐量,该节点 可以部署在Web应用服务器上,也可以部署在专用的服务器上,也开以和DB部署在 同一台服务器上。
网络拓扑
NDB安装
这里使用Auto-Installer安装工具安装,自带GUI操作界面,比较方便。
下载地址
请根据MySQL版本下载对应的NDB安装包,目前
地址:https://dev.mysql.com/downloads/cluster/
包:mysql-cluster-community-7.6.8-1.el7.x86_64.rpm-bundle.tar,mysql-cluster-gpl-7.6.8-el7-x86_64.tar.gz
安装步骤
解压两个包
12tar -xf mysql-cluster-community-7.6.8-1.el7.x86_64.rpm-bundle.tartar -zxf mysql-cluster-gpl-7.6.8-el7-x86_64.tar.gz删除已有的mysql安装包
12345678停止已有的MySQL服务service mysql stop查找rpm包并删除rpm -qa | grep -i mysqlrpm -ev <包名> --nodeps查找遗留文件并删除whereis mysqlfind / -name mysql安装Auto Installer工具并启动,安装过程中会需要其他依赖包,按提示安装即可
12345yum install mysql-cluster-community-common-7.6.8-1.el7.x86_64.rpmyum install mysql-cluster-community-libs-7.6.8-1.el7.x86_64.rpmyum install mysql-cluster-community-client-7.6.8-1.el7.x86_64.rpmyum install mysql-cluster-community-server-7.6.8-1.el7.x86_64.rpmyum install mysql-cluster-community-auto-installer-7.6.8-1.el7.x86_64.rpm将必要的文件拷到相应目录下
12345678cd /mysql-cluster-gpl-7.5.12-el7-x86_64cp bin/ndb_mgm* /usr/local/bincp bin/ndbmtd /usr/local/bincp bin/mysqld /usr/local/bincd /usr/local/binchmod +x ndb_mgm*chmod +x ndbmtdchmod +x mysqld创建
mysql用户及组1234groupadd mysqluseradd -g mysql mysql设置密码,mysql/mysqlpasswd mysql启动
auto-installer安装工具1./usr/bin/ndb_setup.py
Auto-Installer图形化安装步骤
第一次登陆输入一个密码,这里随便填,并且需要填写一个配置文件名,随便填,如test。
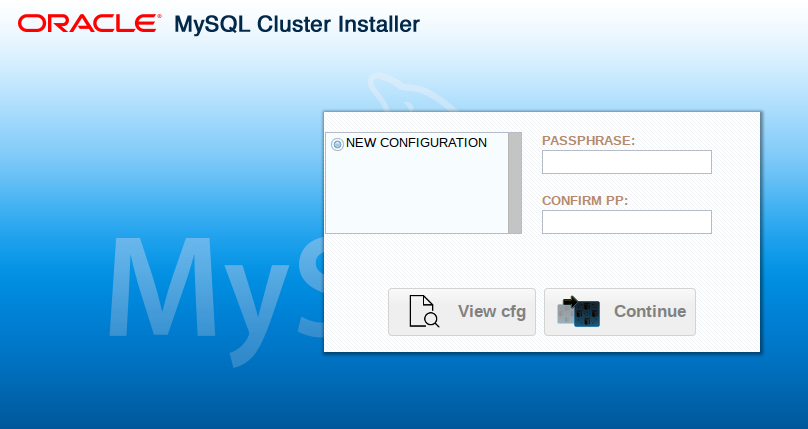
填写集群内机器IP及登陆方式,其他默认即可。

连接主机成功后会显示主机信息。

节点管理,可以创建或删除节点。

创建好之后查看节点分布情况以及管理端口目录等等。

部署启动或停止集群。

各组件运行命令行
123456ndb_mgmndb_mgmd --initial --ndb-nodeid=49 --config-dir=/home/mysql/MySQL_Cluster/49/ --config-file=/home/mysql/MySQL_Cluster/49/config.inindbdndbmtd --ndb-nodeid=1 --ndb-connectstring=10.182.172.148:1186mysqldmysqld --defaults-file=/home/mysql/MySQL_Cluster/54/my.cnf使用命令行查看集群状态
12345678910111213141516ndb_mgm-- NDB Cluster -- Management Client --showConnected to Management Server at: localhost:1186Cluster Configuration---------------------[ndbd(NDB)] 1 node(s)id=1 @10.182.173.158 (mysql-5.7.24 ndb-7.6.8, Nodegroup: 0, *)[ndb_mgmd(MGM)] 1 node(s)id=49 @10.182.173.158 (mysql-5.7.24 ndb-7.6.8)[mysqld(API)] 3 node(s)id=53 @10.182.173.158 (mysql-5.7.24 ndb-7.6.8)id=231 (not connected, accepting connect from 10.182.173.158)id=233 (not connected, accepting connect from 10.182.173.158)
连接Mysql客户端及建库建表
|
|
|
|
ClusterJ API 使用
概念介绍
详见官方文档:The ClusterJ API and Data Object Model
接口定义
定义一个数据库对象接口,不用的字段可以不映射。
|
|
基础用法
|
|
高级使用
可以做批量插入、删除、修改、QueryBuilder等操作。
详见官方文档:Usage of ClusterJ
JDBC使用
因为集群提供了Mysqld服务,所以我们可以通过传统JDBC方式接入NDB集群。
|
|
性能测试
本次性能测试只比较同等条件下,Mysql Cluster NDB的两种Java访问方式的性能差异,并不涉及NDB与单Mysql实例的性能对比。
NDB集群主机配置
| 项目 | 参数 |
|---|---|
| 主机类型 | 虚拟机 |
| 操作系统 | Oracle Linux 7 |
| CPU | 4核 |
| 内存 | 12G |
| 磁盘 | 10G |
测试程序主机配置
| 项目 | 参数 |
|---|---|
| 主机类型 | 虚拟机 |
| 操作系统 | Oracle Linux 7 |
| CPU | 4核 |
| 内存 | 8G |
| 磁盘 | 10G |
测试背景
为检测NDB的Java两种访问方式的效率,故通过Jmeter工具分别对ClusterJ、JDBC进行性能测试对比。为保证两种方式的对等性,ClusterJ只连一个API Node节点,并设置Session最大事务数为64;JDBC只连一个Mysqld服务端,并设置连接池大小为64.
系统架构图
ClusterJ是通过JNI接口直接与NDB的数据节点交互,而JDBC则需要通过Mysqld服务进行数据操作。因此理论上ClusterJ的效率要好与JDBC。

ClusterJ测试工程
参数配置:
|
|
核心代码:
|
|
JDBC测试工程
参数配置:
|
|
核心代码:
|
|
测试结果
基础数据
ClusterJ访问方式CRUD随线程增加TPS变化数据
| Thread Nums | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| Insert | 785.5 | 1910.4 | 4379.1 | 8067.3 | 14347.7 | 23840.8 | 32547.4 |
| Select | 2513.3 | 5834.3 | 10168.1 | 19461.6 | 31622.1 | 39215.3 | 42834.8 |
| Update | 522.4 | 1294.4 | 3105.4 | 5512.4 | 9937.7 | 16443.7 | 24056.1 |
| Delete | 572.5 | 1436.9 | 3284.2 | 5940.7 | 10827.8 | 17632.7 | 25755.6 |
ClusterJ访问方式CRUD随线程增加CUP Load变化数据
| Thread Nums | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| Insert | 5.5 | 9.5 | 18.5 | 24.3 | 28 | 32 | 35 |
| Select | 4 | 7 | 10 | 15 | 18.3 | 19 | 16.3 |
| Update | 8.5 | 16 | 18 | 24.5 | 28.8 | 33.8 | 37.5 |
| Delete | 5.5 | 11.3 | 16 | 23.5 | 27 | 31.3 | 38.3 |
JDBC访问方式CRUD随线程增加TPS变化数据
| Thread Nums | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| Insert | 443.2 | 1051.3 | 2546.3 | 5187.9 | 9304.8 | 14925.8 | 21054.6 |
| Select | 1013.1 | 2345.4 | 5555.3 | 10550.4 | 16860.4 | 21452.9 | 23496.7 |
| Update | 521.3 | 1193.1 | 2717.2 | 5618.7 | 10418 | 16751 | 23039.1 |
| Delete | 551.3 | 1223.6 | 2851.6 | 5991.4 | 10945 | 17887.7 | 24930.1 |
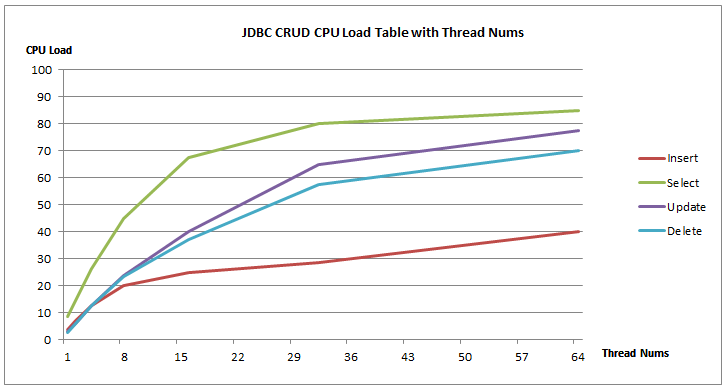
JDBC访问方式CRUD随线程增加CUP Load变化数据
| Thread Nums | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| Insert | 3.8 | 7 | 12.5 | 20 | 25 | 28.8 | 40 |
| Select | 8.5 | 14.5 | 26.3 | 45 | 67.5 | 80 | 85 |
| Update | 3 | 6 | 12.5 | 23.8 | 40 | 65 | 77.5 |
| Delete | 2.8 | 6 | 12.5 | 23.3 | 37.3 | 57.5 | 70 |
TPS趋势对比图
Insert操作

Select操作

Update操作

Delete操作

CPU Load趋势图
ClusterJ CRUD操作

JDBC CRUD操作
结论分析
由上述几张图可知,Select操作ClusterJ方式要比JDBC方式快两倍左右,Insert操作快1.5倍左右,而Update、Delete操作性能基本相当。
ClusterJ访问方式基于JNI接口直接访问数据节点NDB Node,因此比JDBC方式效率要高很多。对于Update、Delete操作,ClusterJ需要通过Session先查询出来,然后再对对象进行下一步操作,实际上做了两步操作,因此在效率上比没有出现预想的比JDBC高。
在测试集群中,NDB Cluster的数据节点有两个,MySQL服务端节点一个。使用ClusterJ是直连数据节点,压力是均匀分布在两台机器上;而通过JDBC连接时,压力全部都在MySQL节点上。因此,使用ClusterJ要比JDBC方式对数据库主机的压力要小得多。
但是ClusterJ同时只能操作一个表对象,不能进行多张表之间的Join操作,因此局限性也是显而易见的。
测试源码
GitHub地址:ndb-practice