
Kafka概述
Apr 12, 2018
kafka是一个分布式的,可分区的,可备份的日志提交服务,它使用独特的设计实现了一个消息系统的功能。
Kafka is a distributed, partitioned, replicated commit log service. It provides the functionality of a messaging system, but with a unique design.
专业术语
- Topic:指Kafka处理的消息源的不同分类;
- Partition:Topic物理上的分组,一个topic可以设置为多个partition,每个partition都是一个有序的队列,partition中的每条消息都会被分配一个有序的id(offset);
- Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发送一些消息;
- Producers:消息生产者,即向Kafka的一个topic发送消息(producer可以选择向topic哪一个partition发送数据)。
- Consumers:消息消费者,接收topics并处理其发布的消息,同一个topic的数据可以被多个consumer接收;
- Broker:缓存代理,Kafka集群中的一台或多台服务器统称为broker。
使用场景
- 作为消息系统:具备两个重要模块,队列与发布-订阅。能够保证消息严格有序,通过partition增加并行度。
- 作为存储系统:多备份,大容量存储特性,使Kafka能够成为一种高性能、低延迟、具备日志存储、备份和传播功能的分布式文件系统。
- 作为流处理平台:从输入Topic取数据,经过聚合、join等复杂处理后再写入输出Topic。
基础架构
Kafka集群典型架构:
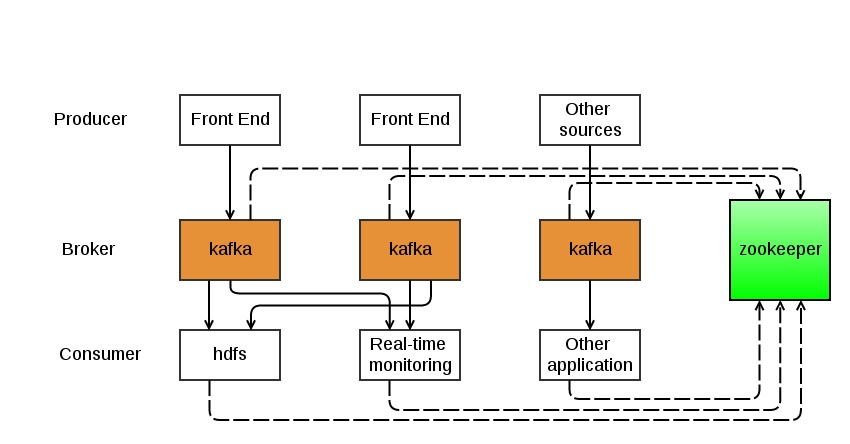
消息生产与消费模式:

快速使用
Step1 下载压缩包
|
|
Step2 启动服务
|
|
Step3 创建Topic
|
|
Step4 生产消息
|
|
Step5 消费消息
|
|
注意事项
Java参数
JDK8且使用G1垃圾收集器
|
|
操作系统
- 低CPU,高内存
- 文件描述符限制100k+
- 文件系统: EXT 或 XFS
Broker重要配置
log.retention.{ms, minutes, hours}:日志保存时长,默认7天。log.retention.bytes:日志删除的尺寸阈值,默认无阈值。message.max.bytes:允许的最大的一个批次的消息大小。delete.topic.enable:默认为 false,是否允许通过 admin tool 来删除 topic;min.insync.replicas= 2:当 Producer 的 acks 设置为 all 或 -1 时,min.insync.replicas代表了必须进行确认的最小 replica 数,如果不够的话 Producer 将会报NotEnoughReplicas或NotEnoughReplicasAfterAppend异常;zookeeper.session.timeout.ms:zookeeper会话超时时间,默认6s,建议设置为30s;num.io.threads:默认为8,KafkaRequestHandlerPool 的大小。
Producer重要配置
batch.size:该值设置越大,吞吐越大,但延迟也会越大;linger.ms:表示 batch 的超时时间,该值越大,吞吐越大、但延迟也会越大;max.in.flight.requests.per.connection:默认为5,表示 client 在 blocking 之前向单个连接(broker)发送的未确认请求的最大数,超过1时,将会影响数据的顺序性;compression.type:压缩设置,会提高吞吐量;acks:此配置是 Producer 在确认一个请求发送完成之前需要收到的反馈信息的数量。 这个参数是为了保证发送请求的可靠性。以下配置方式是允许的:acks=0如果设置为0,则 producer 不会等待服务器的反馈。该消息会被立刻添加到 socket buffer 中并认为已经发送完成。在这种情况下,服务器是否收到请求是没法保证的,并且参数retries也不会生效(因为客户端无法获得失败信息)。每个记录返回的 offset 总是被设置为-1。acks=1如果设置为1,leader节点会将记录写入本地日志,并且在所有 follower 节点反馈之前就先确认成功。在这种情况下,如果 leader 节点在接收记录之后,并且在 follower 节点复制数据完成之前产生错误,则这条记录会丢失。acks=all如果设置为all,这就意味着 leader 节点会等待所有同步中的副本确认之后再确认这条记录是否发送完成。只要至少有一个同步副本存在,记录就不会丢失。这种方式是对请求传递的最有效保证。acks=-1与acks=all是等效的。
Consumer重要配置
fetch.min.bytes:消费批次大小。fetch.max.wait.ms:消费批次最大等待时间。max.poll.interval.ms:调用poll()之后延迟的最大时间,超过这个时间没有调用poll()的话,就会认为这个 consumer 挂掉了,将会进行 rebalance;max.poll.records:当调用poll()之后返回最大的 record 数,默认为500;session.timeout.ms:会话超时时间;
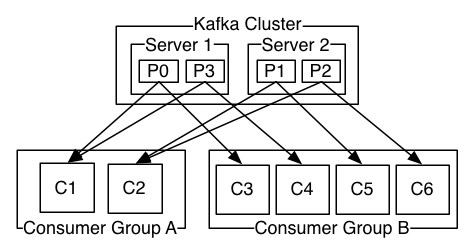
关于Partition
Consumer group中消费者实例与partition关系是:
- 如果group中的consumer数小于topic中的partition数,那么group中的consumer就会消费多个partition;
- 如果group中的consumer数等于topic中的partition数,那么group中的一个consumer就会消费topic中的一个partition;
- 如果group中的consumer数大于topic中的partition数,那么group中就会有一部分的consumer处于空闲状态。
关于Replication
Kafka的副本多少决定于几个参数
- broker中
default.replication.factor - topic中
--replicated-factor,此值会覆盖broker配置里的默认值
示例:
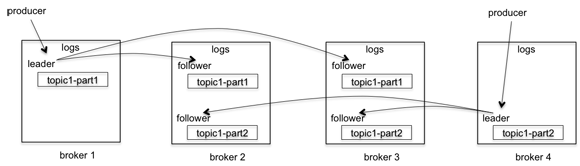
上图中有四个broker,一个topic,2个分区,复制因子是3。当producer发送一个消息的时候,它会选择一个分区,比如topic1-part1分区,将消息发送给这个分区的leader, broker2、broker3会拉取这个消息,一旦消息被拉取过来,slave会发送ack给master,这时候master才commit这个log。